 TÜRKÇE
TÜRKÇE ENGLISH
ENGLISH - +90 216 455-1865
- info@compecta.com
THE WORLD’S FIRST AI SYSTEM BUILT ON NVIDIA A100
NVIDIA DGX™ A100 is the universal system for all AI workloads, offering unprecedented compute density, performance, and flexibility in the world’s first 5 petaFLOPS AI system. NVIDIA DGX A100 features the world’s most advanced accelerator, the NVIDIA A100 Tensor Core GPU, enabling enterprises to consolidate training, inference, and analytics into a unified, easy-to-deploy AI infrastructure that includes direct access to NVIDIA AI experts.
ESSENTIAL BUILDING BLOCK OF THE AI DATA CENTER

The Universal System for Every AI Workload
NVIDIA DGX A100 is the universal system for all AI infrastructure, from analytics to training to inference. It sets a new bar for compute density, packing 5 petaFLOPS of AI performance into a 6U form factor, replacing legacy infrastructure silos with one platform for every AI workload.

DGXperts: Integrated Access to AI Expertise
NVIDIA DGXperts are a global team of 16,000+ AI-fluent professionals who have built a wealth of experience over the last decade to help you maximize the value of your DGX investment.

Fastest Time To Solution
NVIDIA DGX A100 is the world’s first AI system built on the NVIDIA A100 Tensor Core GPU. Integrating eight A100 GPUs with up to 640GB of GPU memory, the system provides unprecedented acceleration and is fully optimized for NVIDIA CUDA-X™ software and the end-to-end NVIDIA data center solution stack.

Unmatched Data Center Scalability
NVIDIA DGX A100 features Mellanox ConnectX-6 VPI HDR InfiniBand/Ethernet network adapters with 500 gigabytes per second (GB/s) of peak bi-directional bandwidth. This is one of the many features that make DGX A100 the foundational building block for large AI clusters such as NVIDIA DGX SuperPOD™, the enterprise blueprint for scalable AI infrastructure.
Game Changing Performance
TRAINING
DLRM Training
Up to 3X Higher Throughput for AI Training on Largest Models
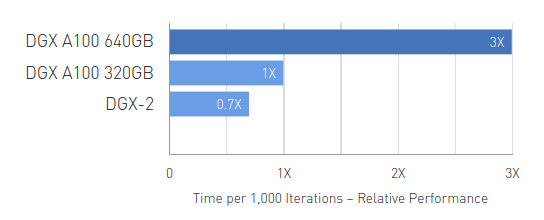
DLRM on HugeCTR framework, precision = FP16 | 1x DGX A100 640GB batch size = 48 | 2x DGX A100 320GB batch size = 32 | 1x DGX-2 (16x V100 32GB) batch size = 32. Speedups Normalized to Number of GPUs.
INFERENCE
RNN-T Inference: Single Stream
Up to 1.25X Higher Throughput for AI Inference
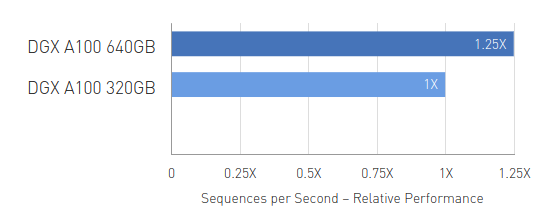
MLPerf 0.7 RNN-T measured with (1/7) MIG slices. Framework: TensorRT 7.2, dataset = LibriSpeech, precision = FP16.
DATA ANALYTICS
Big Data Analytics Benchmark
Up to 83X Higher Throughput than CPU, 2X Higher Throughput than DGX A100 320GB
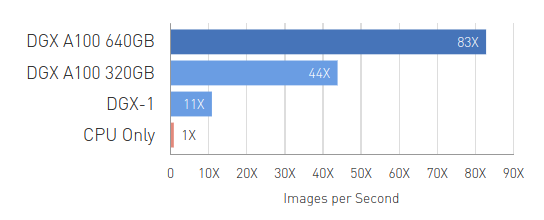
Big data analytics benchmark | 30 analytical retail queries, ETL, ML, NLP on 10TB dataset | CPU: 19x Intel Xeon Gold 6252 2.10 GHz, Hadoop | 16x DGX-1 (8x V100 32GB each), RAPIDS/Dask | 12x DGX A100 320GB and 6x DGX A100 640GB, RAPIDS/Dask/BlazingSQL. Speedups Normalized to Number of GPUs
EXPLORE THE POWERFUL COMPONENTS OF DGX A100
1 8x NVIDIA A100 GPUs with up to 640 GB Total GPU Memory
12 NVLinks/GPU, 600 GB/s GPU-to-GPU Bi-directonal Bandwidth
2 6x NVIDIA NVSwitches
4.8 TB/s Bi-directional Bandwidth, 2X More than Previous Generation NVSwitch
3 10X MELLANOX CONNECTX-6 200 Gb/s NETWORK INTERFACE
500 GB/s Peak Bi-directional Bandwidth
4 Dual 64-Core AMD CPUs and 2 TB System Memory
3.2X More Cores to Power the Most Intensive AI Jobs
5 30 TB Gen4 NVME SSD
50 GB/s Peak Bandwidth, 2X Faster than Gen3 NVME SSDs

Deploy Quickly and Simply
The turn-key NVIDIA DGX A100 system provides plug-and-play setup and takes you from power-on to AI in minutes. AI infrastructure reimagined, optimized, and ready for enterprise AI. Unlock AI in your organization today!
Download Datasheet (PDF)Stay Ahead of the Competition
NVIDIA DGX A100 is engineered to be the essential instrument that delivers the fastest solutions for every AI workload. Run data analytics, training, and inference workloads on the same system.
Check out the infographic (PDF)Maximize Your Investment
Get the support you need to improve productivity and reduce system downtime. Hardware and software support gives you access to NVIDIA deep learning expertise and includes cloud management services, software upgrades and updates, and priority resolution of your critical issues.
Learn More About SupportOrder your NVIDIA DGX A100 Today
Build Your Enterprise-Grade Private Cloud for AI. Purchase NVIDIA DGX systems from the certified partners who offer full-stack accelerated computing solutions from NVIDIA.
NVIDIA Academic discounts available. Please contact for eligibility requirements and legal terms and conditions.
Get more information!
Our experts can answer all your questions. Please reach us via mail or phone.